Designing a High Performance RDBMS Buffer Pool
I've been deep in the trenches building SmolDB, a C++20 mini-RDBMS from scratch. The project's goal is to create a database optimized for a specific workload: high-concurrency transactions on relatively small tables, similar to what you might find in a core banking system. This philosophy—high throughput under contention—has driven every single design decision, especially for the component I want to talk about today: the buffer pool.
The buffer pool is the heart of a database's I/O performance. It's the caching layer that sits between the fast CPU and the slow disk. Get it wrong, and it becomes a massive bottleneck, serializing all data access. Get it right, and it enables the database to scale. From day one, I knew this component had to be designed for concurrency. Here’s how I approached it.
The First Idea: The Textbook Approach (and Why It's a Trap)
Every textbook introduces the buffer pool with a simple, centralized design. You have a hash map to look up pages, an LRU list to track eviction candidates, and a single, global std::mutex to protect them both from race conditions.
cpp// The naive (but correct) single-lock design class BufferPool { private: std::mutex global_mutex_; std::unordered_map<PageID, ...> cache_; std::list<Frame> lru_list_; // ... };
This design is easy to reason about and is guaranteed to be correct. But for SmolDB, it was a non-starter.
The Verdict: Rejected. A single global lock means that every single page request—whether it's a cache hit or miss, for reading or writing—has to wait in a single file line. With our target of handling thousands of concurrent operations, this would serialize the entire system and completely violate the project's core philosophy.
###Evaluating High-Concurrency Alternatives
To solve the bottleneck, I had to find a way to allow multiple threads to work in parallel. I seriously considered two main paths.
The "Optimized" Single Lock: What if we keep the single mutex but are extremely clever about minimizing how long we hold it? The idea is to release the lock during any slow I/O operation. For example, when evicting a dirty page, you'd lock, find the victim, unlock, write the page to disk, re-lock, and then finish the metadata update.
The Sharded (or Segmented) Lock: What if we break the buffer pool itself into smaller, independent pieces? We could have an array of "mini-pools" or shards, each with its own lock, its own cache, and its own LRU list. A
PageIDwould be hashed to a specific shard.
At first glance, the "optimized" single lock seems tempting because it maintains a perfect, global LRU eviction policy. However, a deeper analysis of its eviction path revealed a subtle but critical race condition. It was possible for one thread to be evicting a page while another thread grabbed a reference to it, leading to use-after-free errors. For a system where correctness is paramount, this risk was unacceptable.
The Verdict: Sharded Buffer Pool wins. While it sacrifices a perfect global LRU policy for N independent local policies, this is a standard and worthwhile trade-off. The immense gain in concurrency by eliminating the central bottleneck is far more valuable than a slightly more optimal eviction choice. It directly serves the project's goal of high throughput.
The Final Sharded Architecture
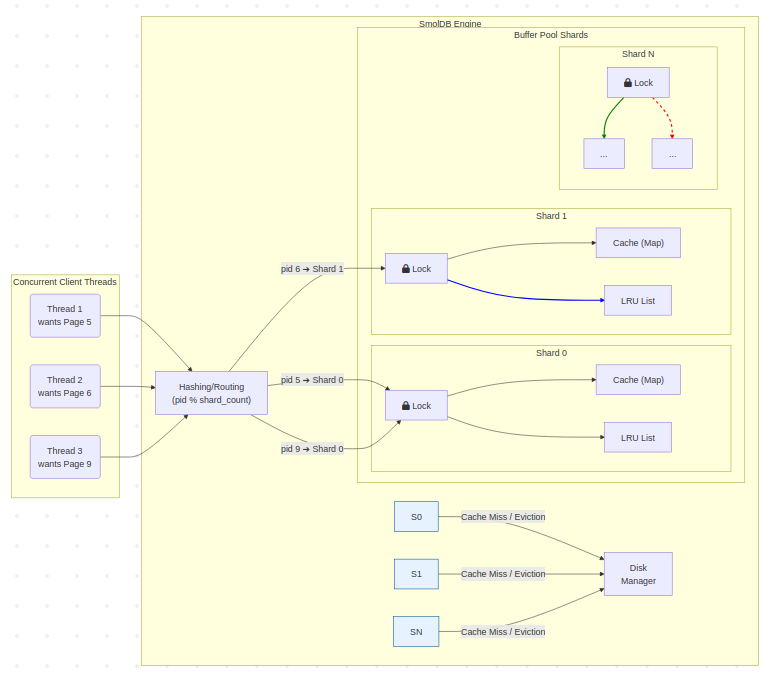
The architecture I settled on is both highly concurrent and safe. The BufferPool class becomes a lightweight coordinator that holds a collection of BufferPoolShard objects.
To ensure stability and prevent the kind of subtle memory bugs that can plague C++ concurrency, I made two key implementation choices:
- The
BufferPoolShardstruct, which contains astd::mutex, is explicitly made non-movable and non-copyable. This uses the C++ type system to enforce correctness. - The
BufferPoolholds these shards in astd::vector<std::unique_ptr<BufferPoolShard>>. This is the idiomatic C++ pattern for creating a collection of non-movable objects, guaranteeing that each shard (and its critical mutex) has a stable memory address for its entire lifetime.
cpp// In bfrpl.h // A self-contained, non-movable shard. struct BufferPoolShard { std::mutex mutex_; std::condition_variable cv_; std::unordered_map<PageID, ...> cache_; std::list<Frame> lru_list_; // ... }; class BufferPool { private: // The vector holds smart pointers, ensuring stable shard addresses. std::vector<std::unique_ptr<BufferPoolShard>> shards_; // A simple hash-based routing function. BufferPoolShard& get_shard(PageID pid) { return *shards_[pid % shard_count_]; } // ... };
When a thread needs to fetch_page(pid), it first hashes the pid to find its designated shard. Then, it locks only that shard's mutex. All other shards remain unlocked and available for other threads to use. This is the source of our scalability.
One of the most powerful aspects of this sharded design is its inherent adaptability. While a simple hash function (page_id % shard_count) is a great general-purpose starting point, SmolDB is designed with specific, known workloads in mind. This architecture gives me a crucial tuning knob. The get_shard() routing function acts as a pluggable partitioning strategy.
In the future, if performance profiling reveals that a few tables are responsible for most of the I/O, I can implement a custom partitioner. For instance, I could create a TableAwarePartitioner that uses metadata from the catalog to ensure all pages belonging to a single hot table are mapped to the same shard. This could improve CPU cache locality and further optimize performance without requiring any changes to the core locking or eviction logic. This flexibility to tailor the physical memory layout to the logical workload is a key advantage that a monolithic design simply can't offer.
Hardening the Design: Lessons from Stress Testing
This design was hardened through a multi-layered testing strategy, because for a concurrent system like this, a passing unit test means very little on its own.
My approach had three tiers:
First, I wrote standard unit tests to validate the fundamentals in a single-threaded context: could a page be pinned, did the LRU list reorder correctly on a hit, and did a full shard correctly evict its least-recently-used page?
Second, I created deterministic concurrency tests to prove specific interactions, such as verifying that threads operating on separate shards experienced zero lock contention.
The final and most critical tier was a non-deterministic fuzz test. I built a "hammer" that spawned dozens of threads to relentlessly and randomly fetch pages, intentionally creating a high-contention perfect storm to force evictions.
Running this test under ThreadSanitizer (TSan) is what flushed out the most subtle bugs: it's exactly how I found the race condition in the Disk_mgr and the subsequent livelock issue in the eviction logic. Only after the design could survive this gauntlet could I be confident that the buffer pool was truly robust and ready for production workloads. We can also take two crucial lessons in systems design.
A Component is Only as Thread-Safe as Its Dependencies: The first runs of the test failed with a segfault inside the
Disk_mgr. My buffer pool logic was correct—multiple threads were safely proceeding in parallel—but they were then making concurrent calls to the shared, unprotectedstd::fstreamobject insideDisk_mgr. The lesson was clear: I had to harden the dependencies too. I added a mutex toDisk_mgrto serialize the I/O calls themselves, fixing the race.Concurrency Requires Fairness: With the crash fixed, the test then revealed a new problem: timeouts. Threads would sometimes fail because they couldn't find a page to evict, even though pages were constantly being unpinned. This was a classic liveness problem. A waiting thread could be unlucky, sleeping through the brief moments a page became available. The solution was to make the system fair by adding active notification. Now, when a
PageGuardis destroyed, it not only decrements the page's pin count but also acquires the shard's lock and signals its condition variable, directly waking up one waiting thread.
Conclusion
The result of this iterative process is a buffer pool that is robust, correct, and highly concurrent. It scales with the number of cores and gracefully handles high-contention scenarios without deadlocking or livelocking.
This journey from a naive design to a hardened, sharded implementation really crystallized the project's philosophy for me. It’s not just about writing code that works in the best case; it’s about analyzing trade-offs, anticipating failure modes, and building a foundation that is resilient by design. With this solid base, I'm now more confident in building out the rest of the database execution engine.
p.s. check out the project here!